NFT-KoolKidz
Jan. 31, 2023

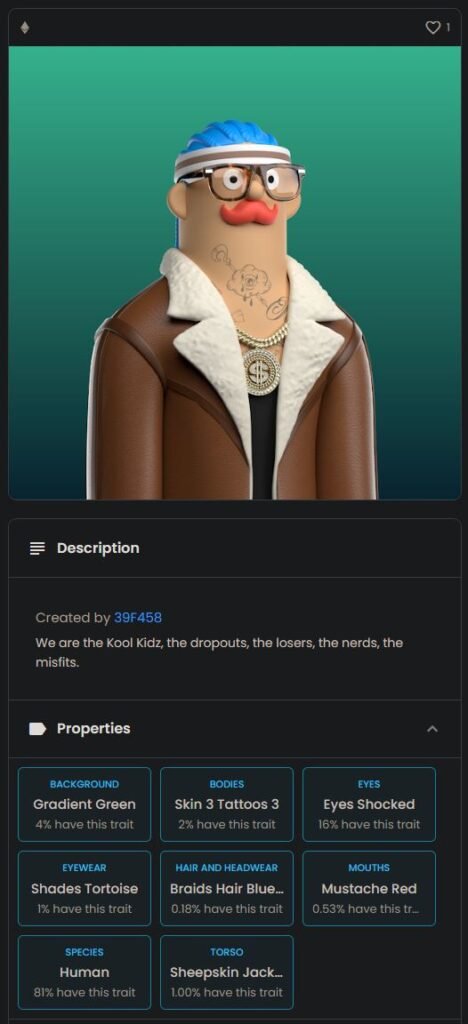
We at Arcade Studio, recently launched an NFT collection of 5000 unique generated “Koolkidz” images and sold around 790 to a community of people that was very excited for the project,
unfortunately we did not sell out on mint day, due to technical issues on the website, which ended up giving a lot potential buyers cold feet! However,
we did manage to deliver all 5000 NFT on reveal day, the results was a colorful range of unique characters, with common and unique traits such as tattoos, long hair, crazy masks and of course even super rares such as aliens,
100 apes and only 25 full golden super rares.

www.arcadestudio.tv

This was my first project that i got to step away from being an animator, and instead finally flex my programming skills while the other artists focused on the art! so,
i ended up building multiple tools within Houdini and outside of Houdini to successfully build an algorithm and workflow that could generate as many characters as i wanted with features like assigning specific assets to build specific character species,
and a feature to add probability to each asset to create rarity, and of course common items … did any of us know what we were doing?? Definitely not, we had a vague idea of what needed to be done, and simply went for it and got it done.
Here is a small glimpse of the tools i built.
Firstly, the project file structure for the assets was kept simple, all the assets was categorized under their main category,

so all eye assets (geo) would fall under the eye directory, and all the mouths assets would fall under the mouth directory and all the assets where in sub directories labeled in numerical order, 1, 2 , 3, 4 etc
so that it was easier to randomize with my Houdini tool.
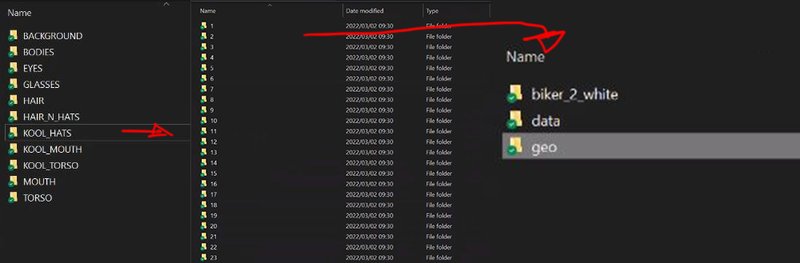
Inside every numerical directory, was a geo, and data directory,
the geo directory held the asset in alembic format, and the data directory simply held a .json file that described the specific individual asset alembic file,
This specific structure and json data was very important in order for my Houdini tool to be able to choose geo based on probability and assign it to a specific character stereo type.
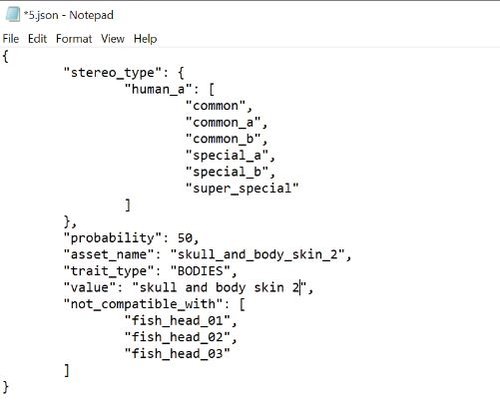
So every asset that was created by the artists. they were each assigned a json file that looks like this,
the “stereo_type” key for this specific asset is only allowed to be chosen and assigned to any other assets that have “common”, “common_a” etc tags, the probability key in the .json file is the probability of the Houdini tool choosing that specific item,
in this case it as a 50% chance of being chosen, a lower number would create rarity to the item, the “asset_name”, “trait_type” and “value” keys is the final names that would appear on OpenSea as an attributes / traits,
and the “not_compatible_with” key is for my Houdini tool to know that this specific asset is not compatible with these assets “fish_head_01” etc and it must not be chosen if fish_head_01 etc has already been chosen.
Considering that this is a lot of alembic files and json files all describing every asset that was made,
it was very tedious to modify these json files by hand, so i ended up making multiple command line tools to help mass tweak and change these json files, saving so much time!
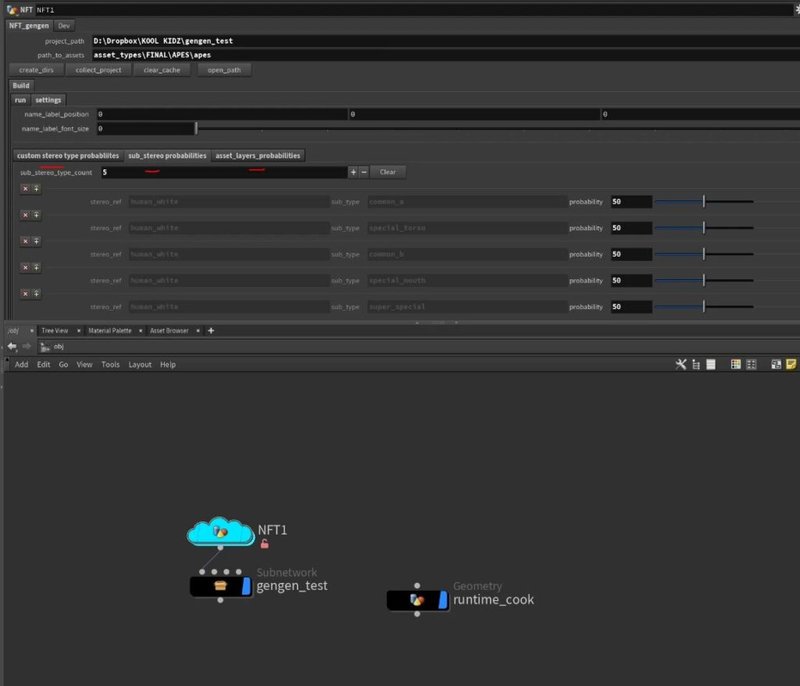
Here is the main Houdini tool that has the algorithm that i built for this specific project, the first step is to ensure paths are correct,
insert the amount of NFTs to generate, and a species name (for OpenSea) once that is completed the next step was to hit the collect_project button,
the collect project button had a simple purpose, and that was to loop through all the asset directories and collect all the json data files, and build / populate the 3 MultiParms with all the assets and their settings such as probability,
by populating the Houdini tool with all this data, this gave the artist an opportunity to experiment with changing any assets probability before the generation process.
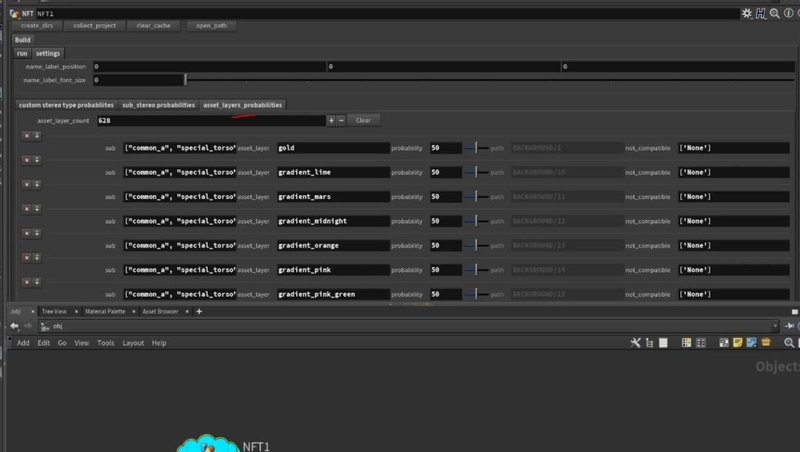
once sub stereo and asset layers settings where tweaked, it was time to hit the generate NFT button!

what the Houdini tool does to build a character, is for loop through all the main directories, bodies, eyes, mouth etc, and then loop again through every asset within that main directory, and read every assets json file,
every json file it reads it then loops through the collected assets in the collected Houdini tools multiparm (image above), to see if the sub stereo types from the JSOn file (common_a, common_b, etc) matches up with the sub in the multiparm,
if it does AND the sub stereo name is NOT part of the not_compatible list, then the Houdini tool will add that asset AND its probability value to a list, ending up with a large temporary python data list of all the compatible assets,
python then looks at all the probability values together within that list, and based on probability values, it will choose an asset from that main directory and import it as an alembic file into Houdini,
and this process keeps looping through every main directory until python has built a complete character,
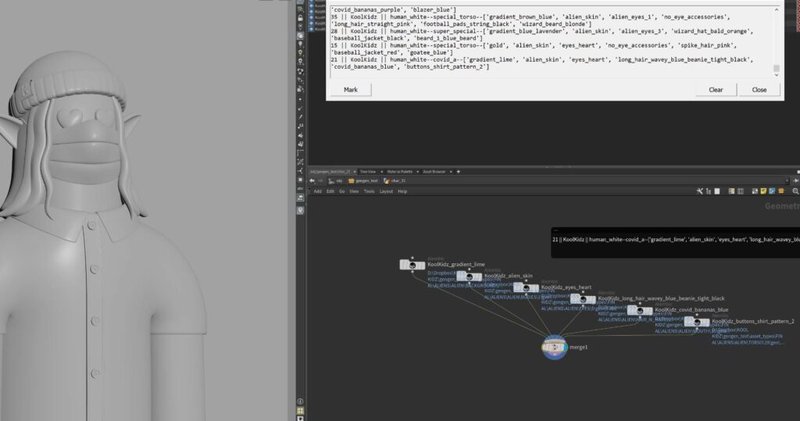
for every asset that gets chosen and imported to create a single character, the Houdini tool connects the alembics up into a single geo node and writes out a new json file,
to describe that newly built NFT as per OpenSea json formatting standards.
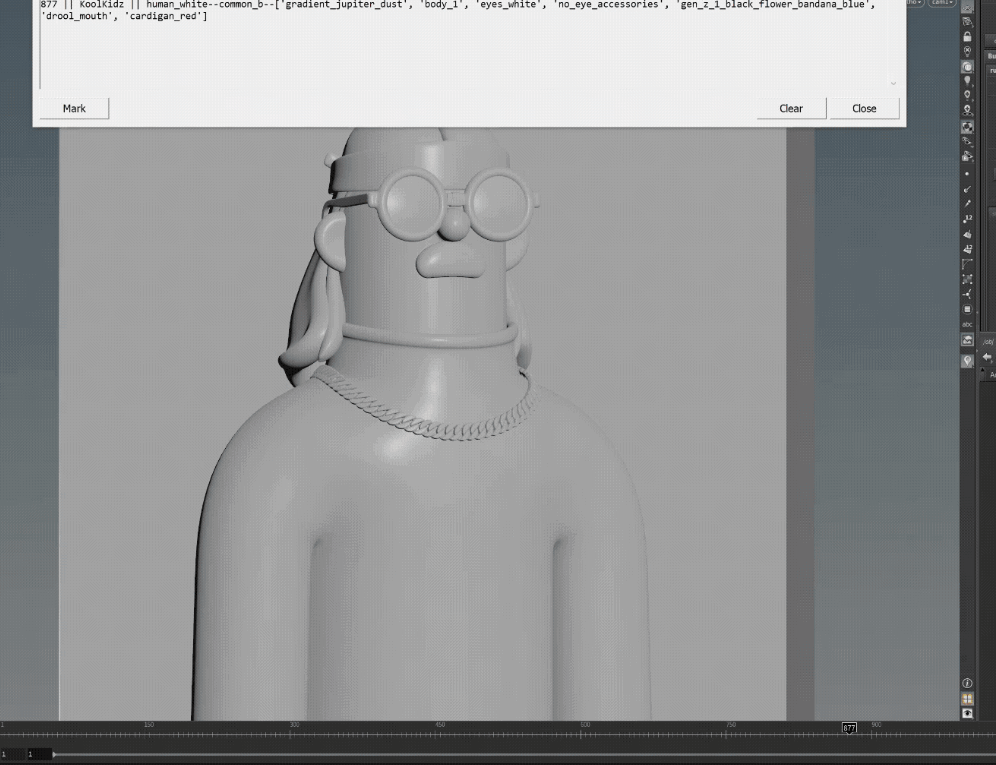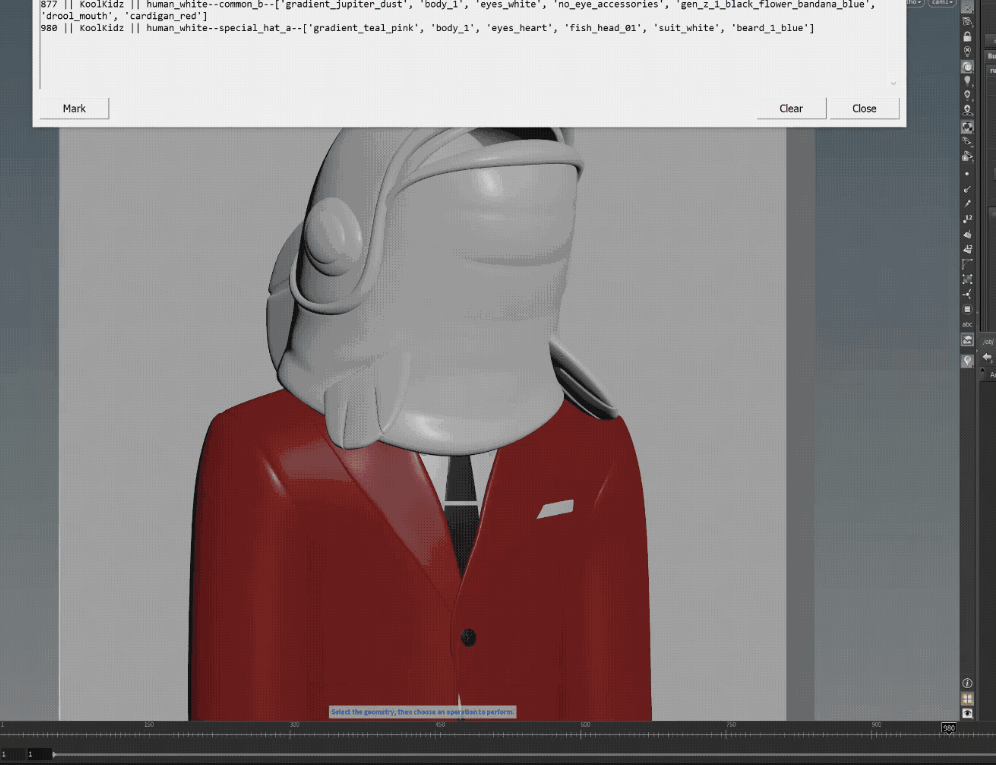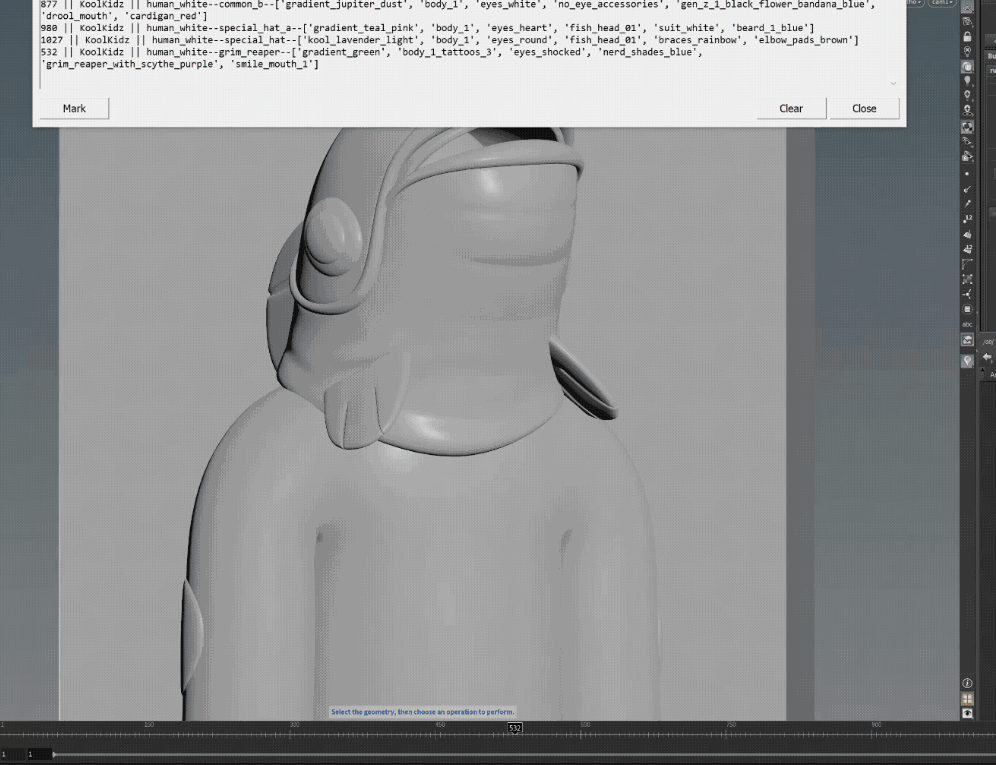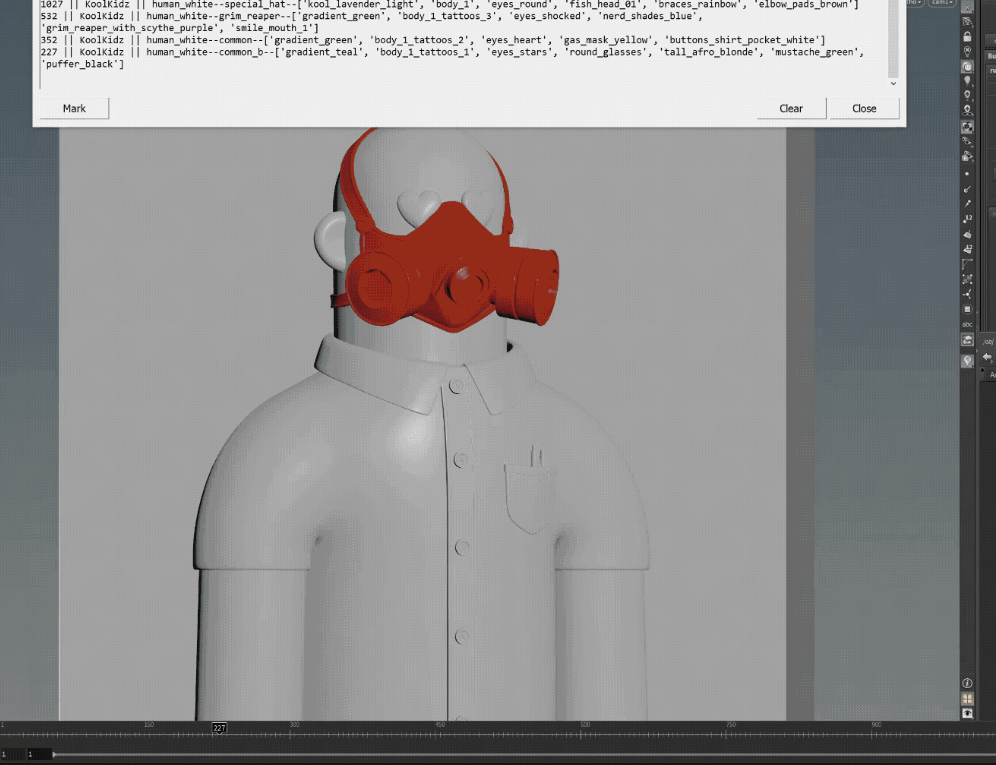
during the generation process, the Houdini tool assigns the final NFT geo to a specific corresponding frame, so that when we render, we can render them out in one go as an image sequence,
however! having all 5000 NFTs all with their unique geo imported into the scene created memory issues within Houdini, it simply was too much geo for the program to handle,
but with a bit of luck i figured out how to bypass this by keeping all the generated NFT characters display flags off by default, and i built a separate tool that when you change frame,
the tool will switch on that specific NFT node only, switch off the previous frames node and clear the cache, this worked well during rendering too.
every asset uvs and shaders were pre-built by our shading and lighting department,
and all that was left was to send it off to the render queue and hand over the 5000 rendered images and json files to the blockchain developers to upload onto opensea for the sale to begin!
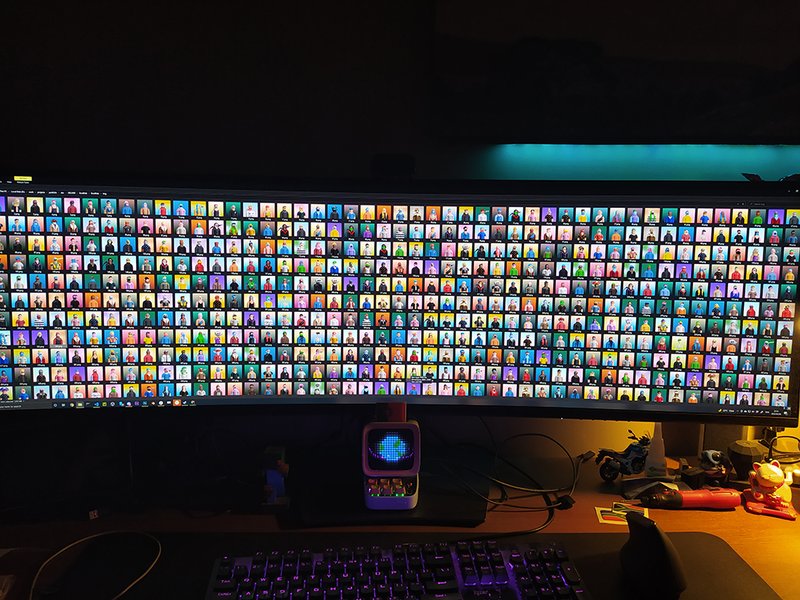
and this is what we ended up with: